
Notice
Link
Recent Posts
Recent Comments
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
Tags
- 연관분석
- yarn 설치 에러
- 코딩테스트
- 행렬
- NumPy
- 부스트캠프
- map
- 딥러닝 개요
- 역전파
- npm install -g yarn 에러
- sql
- 부스트캠프ai
- 프로그래머스 SQL
- inner join
- 컴퓨터 통신
- 쉽게 배우는 데이터 통신과 컴퓨터 네트워크
- MySQL
- gpt-api
- 딥러닝 역사
- ERROR: install is not COMMAND nor fully qualified CLASSNAME.
- gpt-api에러
- TabNet
- HackerRank
- pre-course
- 깃
- python
- pandas
- 컴퓨터통신
- 쉽게 배우는 데이터 통신과 컴퓨터 네트워크 답지
- 프로그래머스
Archives
최말짱 블로그
TabNet 본문
728x90
TabNet
Deep Learning for Tabular data
- Tree 기반 모델의 feature selection 특징을 네트워크 구조에 반영한 딥러닝 모델
- 가공하지 않은 Raw data에서 gradient를 기반한 최적화를 사용함으로써 End-to-End 학습을 실현
- Sequantial attention mechanism을 사용하여 모델의 성능과 해석 용이성을 향상 ⇒ 이전 단계 학습 결과가 다음 단계 Mask 학습에 영향을 주는 연결 구조
- 특징
- Sequential Approach
- 모델을 반복 연결하여 잔차를 보완하는 gradient boosting이 연상되는 구조
- Feature selection
- feature transformer와 attentive transformer 블록을 통과하여 최적 mask를 학습함
- Sequential Approach
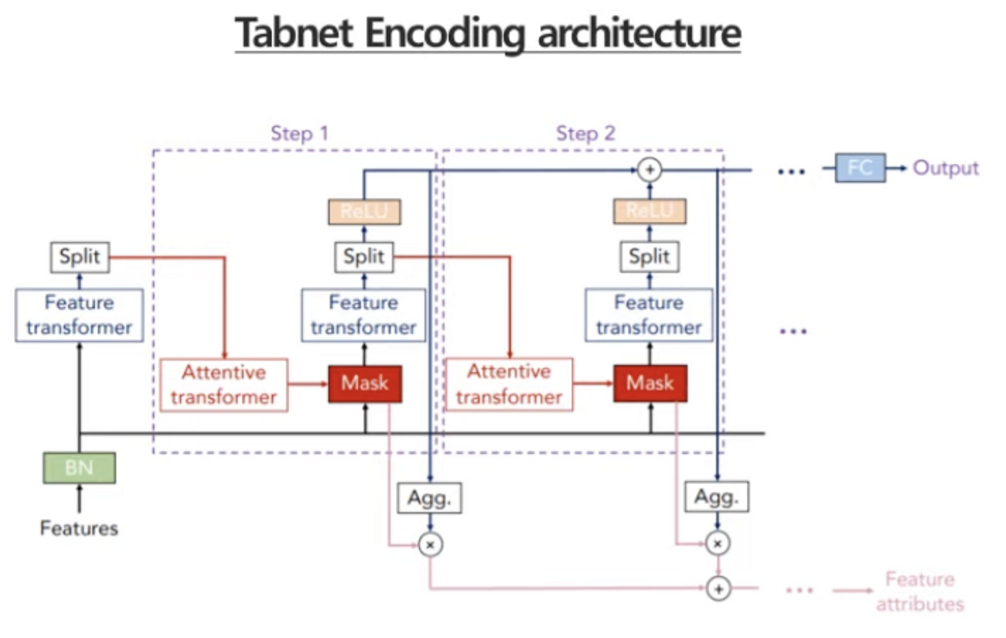
- 블록 1, Shared across decision steps → 모든 step에서 파라미터 공유 ( 전체 네트워크의 글로벌한 특징을 학습 )
- 각각 step에서만 전용으로 사용 ( 로컬적인 속성을 학습 )

- Ghost Batch Norm(BN) → local minima 해결
- Gated Linear Unit → LSTM과 같이 신호의 크기 조절

- Prior Scales : i번째 단계에서 변수의 중복 반영 여부를 결정하는 factor, 선택된 변수의 반영률이 점차 낮아지는 특성
- Sparsemax 함수 :
- softmax의 문제, 발생 가능성이 없는 확률도 0보다 큰 값을 가지게 되면서 불필요한 feature에도 작지만 0이 아닌 가중치가 붙어 연산량이 낭비된다. → 이를 해결한 것이 sparsemax이다.
- o 또는 T로 수렴, 변수의 작동을 조절 ⇒ 추가로 Entmax 함수로도 대체 가능
- Semi-supervised Learning ( 디코딩 ) → 데이터 보간 가능
- 특정한 영역이 masking된 인코딩 데이터를 원본대로 복원할 수 있도록 학습
- 사전 학습을 통한 예측 성능 향상, 학습 시간 단축 및 결측치에 대한 보간 효과
- Attentive Transformer의 Mask값을 활용한 변수 중요도 시각화
- M[i]는 모든 검증 데이터에 대해 각 attentive transformer 단계에서 mask 적용 후 활성화 비율을 표현하며 지역적인 특성을 확인할 수 있음 (중요도 확인 가능, 해석가능)

Result
- 처음에는 reject 되었던 논문
- 10.5 M 사이즈의 Higgs Boson dataset에서는 pretraining의 성능을 추가 입증함
- tabular에서도 괜찮지 않을까
- 내가 논문 리뷰했던
- Tabular Data : Deep Learning is Not All You Need
- 동일한 데이터로 4개의 tabular data용 딥러닝 연구 간 성능 비교 결과, fine tuned XGBoost가 딥러닝 대비 준수한 성능을 나타냄
- 딥러닝 모델과 XGBoost의 앙상블 결합시 가장 우수한 결과를 도출함
- Tabular Data : Deep Learning is Not All You Need
결론적으로
딥러닝은 tabular 데이터에서 해석의 난이도와 학습의 비용에 문제로 인해서 두각을 드러내지 못 했다.
⇒ TabNet에서는 conventional DNN 블록 개념을 도입하여 tree 모델과 같은 해석 용이성을 제공했다.
⇒ attentive transformer 블록 내에 sparsemax, prior scales를 활용하여 변수의 중복 사용을 제한함으로써 변수 마다 중요도를 학습할 수 있도록 고안했다.
'AI' 카테고리의 다른 글
| 1.딥러닝 개요 (0) | 2023.04.17 |
|---|---|
| AUC-ROC 커브 (0) | 2023.01.11 |
| 머신러닝(Machine learning)과 딥러닝(Deep Learning)의 차이 (0) | 2023.01.11 |
| 딥러닝의 역사 (0) | 2022.08.03 |
| RNN (0) | 2022.08.02 |