
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 컴퓨터통신
- 깃
- python
- 쉽게 배우는 데이터 통신과 컴퓨터 네트워크 답지
- 부스트캠프ai
- gpt-api
- 역전파
- sql
- 쉽게 배우는 데이터 통신과 컴퓨터 네트워크
- MySQL
- pre-course
- 프로그래머스 SQL
- 행렬
- yarn 설치 에러
- 딥러닝 역사
- pandas
- TabNet
- ERROR: install is not COMMAND nor fully qualified CLASSNAME.
- gpt-api에러
- HackerRank
- inner join
- 컴퓨터 통신
- 프로그래머스
- NumPy
- npm install -g yarn 에러
- 코딩테스트
- 연관분석
- map
- 부스트캠프
- 딥러닝 개요
최말짱 블로그
데이터 마이닝 방법론(CRISP-DM, KDD) 본문
머신러닝 분석 프로젝트는 어떻게 진행되나?
막막할 땐 잘 정리된 방법론의 절차를 따라 진행하면 쉽게 접근할 수 있을 것이다 !
오늘은 방법론에 대해 알아보자 ㅎㅎ
1) CRPISP-DM 방법론
- Cross- Industry Standard Process for Data Mining
- 분석 프로젝트를 위한 모형 중에 가장 잘 알려진 방법론
- 데이터 마이닝을 위해 만들어 진 방법론이나 예측론, 머신러닝 등 여러 분석적 프로젝트에 이용 될 수 있을 만큼 유연하고 빈틈없다.
- 크게 6가지 단계로 이루어 지며, 각 단계별로 하위 3~4과제로 구성
https://the-modeling-agency.com/crisp-dm.pdf

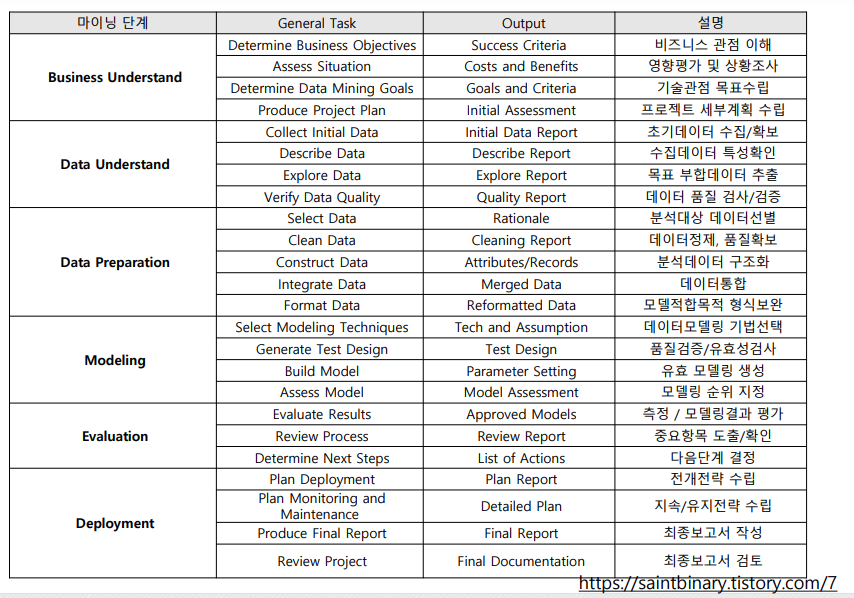
1. 비즈니스 이해
- 분석 프로젝트의 목적을 비즈니스 시각에서 부터 시작하고 그 문제를 머신러닝의 문제로 전환하여 구체화 하는 것이 핵심
- 합리적인 성공의 기준 정의 및 그 목표를 달성 하도록 계획을 세움.
2. 데이터 이해
- 분석을 위한 데이터 파악 및 수집(ETL)과 데이터가 가진 의미를 파악하고 데이터의 품질 확인, 이후 기초탐색을 통해 의미있는 데이터 발견과 가설검증
3. 데이터 준비
- 수집된 각각의 데이터를 머신러닝에 적합한 형태의 데이터로 만들며 최종 데이터 셋을 만드는 과정
- 필요한 데이터를 선택하고 여러 데이터를 조합하여 의미있는 데이터로 정제&가공
4. 모델링
- 다양한 머신러닝 기법의 선택 및 평가를 위한 방안(데이터 및 평가지표) 설정
- 정해진 평가방법을 통해 최적의 알고리즘 선택 및 파라미터 최적화를 통해 최종 모델을 도출
5. 평가
- 선택된 모델이 비즈니스의 목표에 맞는지 확인
- 중요한 비즈니스적 문제가 있었음에도 이를 반영하지 않은 부분이 있는지 평가와 최종적으로 모델링 결과를 사용할지 여부 결정
- 이후 남은 일정과 자원을 고려하여 모델을 적용할지 반복을 통해 모델을 더 향상 시킬지, 후속 프로젝트를 할지 결정
6. 전개(배포)
- 최종 서비스를 위한 준비
- 시스템화에 필요한 정비와 모델의 모니터링 주기/ 평가지표를 정의하여 유지보수 시점 및 방안 도출
- 이후 보고 및 인수 인계를 위한 문서 작성
CRISP-DM 산출물
2) KDD 방법론
- knowledge Discovery in Database
- 기술과 데이터베이스를 중심으로한 인사이트 발굴을 위한 절차와 단계를 정리한 것
- DBMS를 운영하는 조직에서는 쉽고 유용하게 사용될 수 있다. BI(Business Intelligence)라는 용어로 불려지기도 함.
- 즉, KDD는 데이터베이스에서의 데이터를 통해 인사이트를 얻기 위한 표준화된 처리 절차와 방법 !
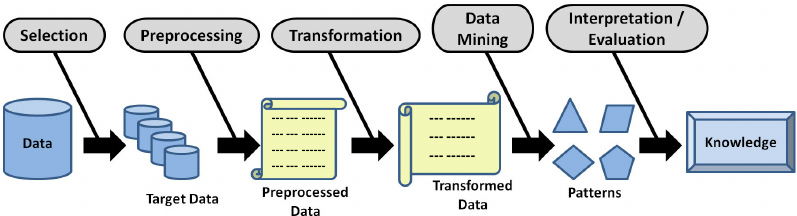
1) selection(추출)
- 선택에 앞서 비즈니스 도메인에 대한 이해와 프로젝트 목표 설정 필수
- Target Data(목표 데이터) 생성
2) Pre-processing(전처리)
- 잡음, 이상치, 결측치 등을 제거
- 추가로 요구되는 데이터 셋이 있을 경우 Selection 프로세스 재실행
3) Transformation(변환)
- 목적에 맞게 변수생성, 선택하고 데이터 차원 축소
- 프로세스 진행을 위해 학습용 데이터(Training Data)와 검증용 데이터(Test Data)로 데이터 분리
4) Data Mining(데이터 마이닝)
- 분석 목적에 맞는 데이터 마이닝 기법, 알고리즘 선택, 패턴찾기, 데이터 분류, 예측 작업
- 필요에 따라 데이터 전처리와 변환 프로세스를 추가 실행
5) Interpretation Evaluation(해석/평가)
- 분석 결과에 대한 해석/평가
- 분석 목적과의 일치성 확인
- 발견된 지식을 업무에 활용
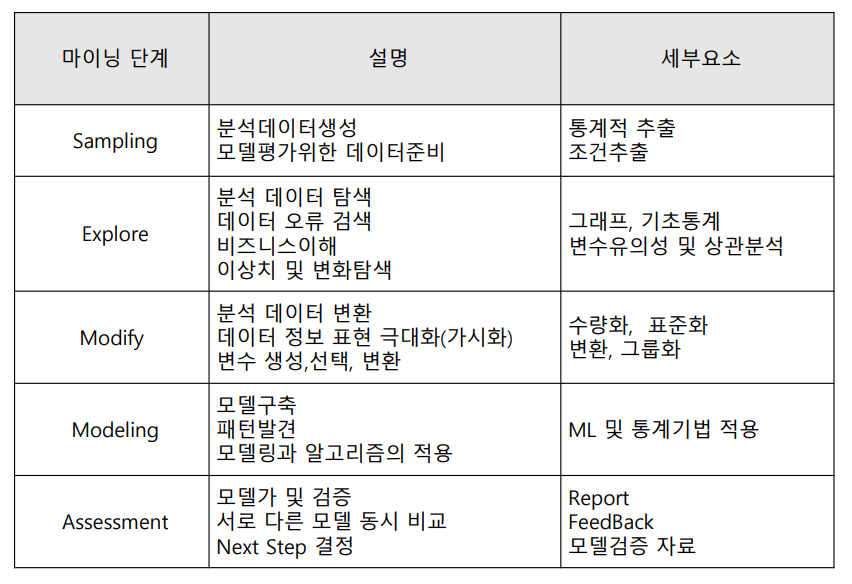
출처 : https://bigdatamaster.tistory.com/11, https://needjarvis.tistory.com/508
데이터 분석 방법론 (KDD, SEMMA, CRISP-DM)
데이터 분석 방법론 (KDD, SEMMA, CRISP-DM) 데이터 분석 방법론 막상 데이터 분석을 하려고 하면 막막할 때가 많습니다...이럴때 미리 잘 정리된 절차와 방법을 따라서 하나씩 진행한다면 쉽게 접근할
bigdatamaster.tistory.com